
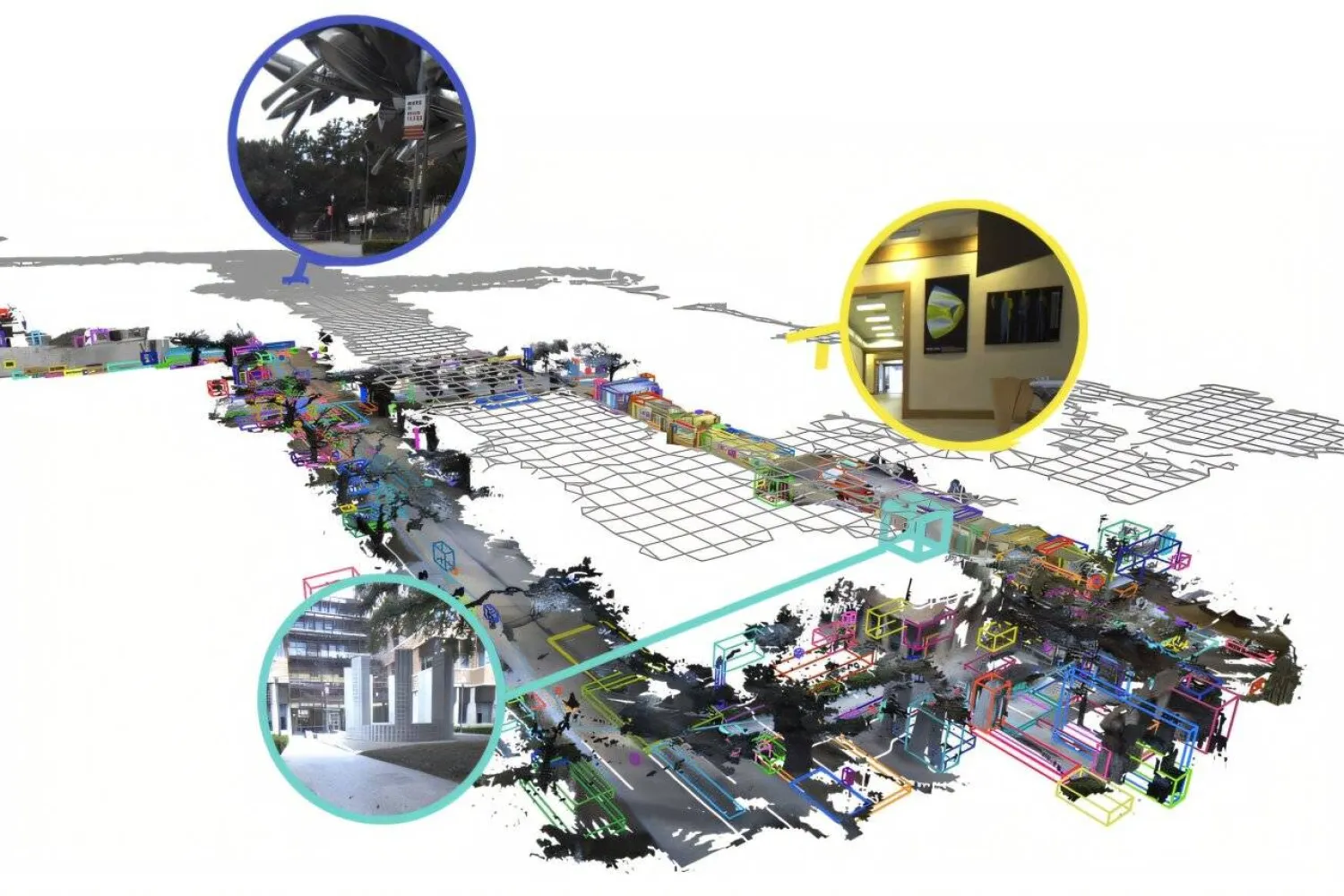
طوّر باحثون في معهد ماساتشوستس للتكنولوجيا إطاراً جديداً للذاكرة طويلة الأمد، يهدف إلى تمكين الروبوتات من تذكّر الأماكن والأشياء والأحداث التي رصدتها في أثناء تحركها في البيئات الحقيقية.
وقد يتيح هذا التوجه مستقبلاً للروبوت الإجابة عن أسئلة بسيطة مثل: أين تركت محفظتي؟ أو أين وُضع الجزء الذي كنا نعمل عليه بالأمس؟ لكن النظام لا يزال مشروعاً بحثياً، ولم يتحول بعد إلى أداة منزلية جاهزة للبحث عن الأشياء المفقودة.
يحمل النظام اسم «دام» ( DAAAM) وهو اختصار لعبارة تعني «وصف أي شيء، في أي مكان، وفي أي وقت». ويجمع بين الخرائط الثلاثية الأبعاد والرؤية الحاسوبية والنماذج اللغوية، لبناء ذاكرة مكانية وزمنية يستطيع الروبوت البحث فيها باستخدام اللغة الطبيعية.
ذاكرة مرتبطة بالعالم الحقيقي
تستطيع روبوتات كثيرة اليوم رسم خريطة للمكان وتحديد موقعها داخله، لكن هذه الخرائط تركز غالباً على الأبعاد الهندسية والعوائق والمسارات، ولا تحتفظ بالضرورة بوصف غني للأشياء الموجودة في كل موقع.
أما نماذج الرؤية متعددة الوسائط، فيمكنها التعرف على محتوى الصور ووصف الأجسام والمشاهد، لكنها قد لا تكون مصممة لتخزين هذه المعلومات داخل خريطة واسعة ومتغيرة عبر الزمن.
يحاول «DAAAM» الجمع بين القدرتين، على سبيل المثال، عند تحركه داخل منزل أو مصنع أو حرم جامعي، يسجل الأشياء التي يراها ويربط أوصافها بمواقعها على خريطة ثلاثية الأبعاد.
فقد يتذكر أن دراجة حمراء ذات إطار مثقوب كانت موجودة في موقف خارج مبنى معين، أو أن قطعة صناعية تُركت في صندوق تخزين في منطقة محددة خلال اليوم السابق. ويسمح هذا الربط للروبوت بفهم السؤال من حيث المكان والزمن والصفات، بدلاً من البحث عن اسم الشيء وحده.
اختيار الصور الأكثر فائدة
تتمثل إحدى العقبات أمام بناء هذا النوع من الذاكرة في كمية المعلومات التي يلتقطها الروبوت. فقد تمر أمام كاميراته مئات الأشياء خلال دقائق، بينما يستغرق وصف كل جسم على حدة وقتاً وقدرة حاسوبية كبيرين. لمعالجة ذلك، يجمع النظام الأشياء المتقاربة في مجموعات، ثم يختار لقطات رئيسية توفر أوضح رؤية لأكبر عدد منها. وبعد ذلك، يمكنه وصف عدة أشياء بالتوازي بدلاً من تحليل كل جسم بصورة منفصلة.
ويقول الباحثون إن هذه الطريقة تسرّع عملية إنشاء الأوصاف بنحو عشرة أضعاف، ما يسمح للنظام بالعمل في الوقت الحقيقي داخل بيئات واسعة. كما يحاول الإطار تجنب تكرار معالجة الجسم نفسه؛ إذ يسجل وصفه مرة واحدة ثم يربطه بموقعه داخل الخريطة.

البحث باللغة الطبيعية
بعد بناء الذاكرة، يظل التحدي في الوصول بسرعة إلى المعلومة المناسبة وسط قاعدة بيانات كبيرة من المواقع والأجسام والأوصاف. ولهذا يستخدم النظام نموذجاً لغوياً يمكنه اختيار أدوات بحث مختلفة بحسب السؤال؛ فإذا سأل المستخدم عن منحوتة رآها الروبوت، يستطيع النظام البحث دلالياً عن كلمة «منحوتة». أما إذا تضمن السؤال موقع مبنى معين، فيمكنه استخدام أداة بحث مكانية. وتسمح هذه الآلية للنظام بتقسيم السؤال إلى عناصر محددة، بدلاً من الاعتماد على النموذج اللغوي وحده لتخمين الإجابة. ويرى الباحثون أن ذلك يساعد على تقليل الهلوسة؛ لأن الإجابة تستند إلى سجلات فعلية جمعها الروبوت من البيئة. وفي الاختبارات، تفوّق «DAAAM» على طرق منافسة بنسب تراوحت بين 21 و53 في المائة، بحسب نوع السؤال المستخدم في التقييم.
من المصانع إلى الواقع المعزز
قد تكون المصانع من أوائل البيئات المستفيدة من ذاكرة مكانية طويلة الأمد، حيث يمكن للعامل أن يطلب من روبوت العثور على أداة أو مكوّن تُرك في وردية سابقة، بدلاً من توجيهه يدوياً إلى الموقع. كما يمكن استخدام الفكرة في أنظمة الواقع المعزز المخصصة لفنيي الصيانة، بحيث تساعدهم على تذكّر مواضع المعدات أو رصد التغيرات غير المعتادة. وقد تفيد أيضاً في الملاحة داخل المباني والأماكن المعقدة.
لكن قدرة النظام الحالية تتركز على الأشياء والمواقع التي رصدها الروبوت بالفعل. فهو لا يعرف مكان المفاتيح إلا إذا كانت كاميراته قد شاهدتها، وربطت وصفها بموقع واضح، واحتفظت بهذه المعلومة داخل الذاكرة.
الخطوات التالية
يعمل الباحثون الآن على توسيع الإطار حتى يتمكن من تسجيل الأحداث المهمة، وليس فقط أوصاف الأجسام والمواقع. كما يخططون لإضافة مستويات ثقة إلى الإجابات، كي يوضح الروبوت مدى يقينه من المعلومة التي يقدمها. والهدف الأبعد هو تطوير روبوتات عامة تستطيع تنفيذ أنواع مختلفة من المهام بناءً على أوامر لغوية بسيطة. ويتطلب ذلك ألا ترى البيئة فقط، بل إن تتذكر كيف تغيرت بمرور الوقت، وأن تسترجع التفاصيل المناسبة عند الحاجة. بهذا المعنى، لا يقدم البحث روبوتاً منزلياً يعثر فوراً على المفاتيح المفقودة، لكنه يضع أساساً لذاكرة تجعل الآلات أكثر قدرة على فهم العالم بالطريقة التي يستخدم بها البشر المكان والزمن واللغة.





